在 Spring Boot 中获取 YAML 配置数据有多种方式,一般使用两种,一种@value注解,一种@ConfigurationProperties注解
1
2
3
4
5
6
7
8
9
10
11
12
13
|
@Component
public class MyService {
@Value("${app.secret.key}")
private String secretKey;
@Value("${app.secret.timeout:3600}") // 使用默认值3600
private int timeout;
public void printSecret() {
System.out.println("Secret Key: " + secretKey);
}
}
|
1
2
3
4
5
6
|
# application.yml
app:
secret:
key: "my-secret-key-123"
timeout: 7200
algorithm: "AES"
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
// 配置类
@Component
@ConfigurationProperties(prefix = "app.secret")
@Data // Lombok,或手动生成getter/setter
public class SecretProperties {
private String key;
private int timeout;
private String algorithm;
}
// 使用方式
@Service
public class SecurityService {
@Autowired
private SecretProperties secretProperties;
public void test() {
System.out.println("Key: " + secretProperties.getKey());
System.out.println("Timeout: " + secretProperties.getTimeout());
}
}
|
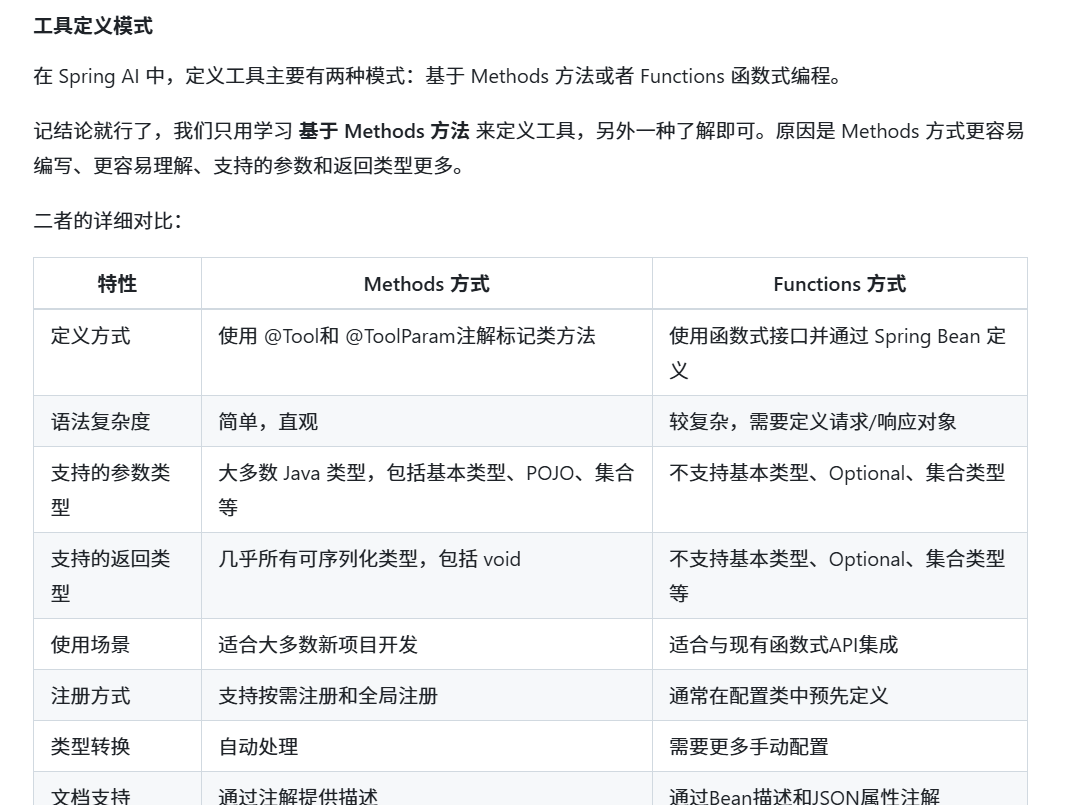
Spring AI 核心特性
以下核心特性基于 Spring AI 官方文档:
-
跨 AI 供应商的可移植 API 支持:适用于聊天、文本转图像和嵌入模型,同时支持同步和流式 API 选项,并可访问特定于模型的功能。
-
支持所有主流 AI 模型供应商:如 Anthropic、OpenAI、微软、亚马逊、谷歌和 Ollama,支持的模型类型包括:聊天补全、嵌入、文本转图像、音频转录、文本转语音。
-
结构化输出:将 AI 模型输出映射到 POJO(普通 Java 对象)。
-
支持所有主流向量数据库:如 Apache Cassandra、Azure Cosmos DB、Azure Vector Search、Chroma、Elasticsearch、GemFire、MariaDB、Milvus、MongoDB Atlas、Neo4j、OpenSearch、Oracle、PostgreSQL/PGVector、Pinecone、Qdrant、Redis、SAP Hana、Typesense 和 Weaviate。
-
跨向量存储供应商的可移植 API:包括新颖的类 SQL 元数据过滤 API。
-
工具/函数调用:允许模型请求执行客户端工具和函数,从而根据需要访问必要的实时信息并采取行动。
-
可观测性:提供与 AI 相关操作的监控信息。
-
文档 ETL 框架:适用于数据工程场景。
-
AI 模型评估工具:帮助评估生成内容并防范幻觉响应。
-
Spring Boot 自动配置和启动器:适用于 AI 模型和向量存储。
-
ChatClient API:与 AI 聊天模型通信的流式 API,用法类似于 WebClient 和 RestClient API。
-
Advisors API:封装常见的生成式 AI 模式,转换发送至语言模型(LLM)和从语言模型返回的数据,并提供跨各种模型和用例的可移植性。
-
支持聊天对话记忆和检索增强生成(RAG)。
工具调用能力,结构化输出,对于数据的封装,以及RAG能力,我觉得是springai框架中最突出的能力,也是符合市场需求的能力,简化的ai应用开发,让开发者更注重业务
4种AI大模型接入方式优缺点对比
| 接入方式 |
优点 |
缺点 |
适用场景 |
| SDK接入 |
- 类型安全,编译时检查
- 完善的错误处理
- 通常有详细文档
- 性能优化好 |
- 依赖特定版本
- 可能增加项目体积
- 语言限制 |
- 需要深度集成
- 单一模型提供商
- 对性能要求高 |
| HTTP接入 |
- 无语言限制
- 不增加额外依赖
- 灵活性高 |
- 需要手动处理错误
- 序列化/反序列化复杂
- 代码冗长 |
- SDK不支持的语言
- 简单原型验证
- 临时性集成 |
| Spring AI |
- 统一的抽象接口
- 易于切换模型提供商
- 与Spring生态完美融合
- 提供高级功能 |
- 增加额外抽象层
- 可能不支持特定模型的特性
- 版本还在快速迭代 |
- Spring应用
- 需要支持多种模型
- 需要高级AI功能 |
| LangChain4j |
- 提供完整的AI应用工具链
- 支持复杂工作流
- 丰富的组件和工具
- 适合构建AI代理 |
- 学习曲线较陡
- 文档相对较少
- 抽象可能引入性能开销 |
- 构建复杂AI应用
- 需要链式操作
- RAG应用开发 |
springai中调用大模型的方式
使用chatmodel,可以对大模型进行简单的调用,使用.call方法就可以直接调用大模型进行对话
使用chatclient,一个大模型的客户端,他支持更多的链式调用,比如springai最核心的advisor模式
1
2
3
4
5
6
7
8
9
|
// 基础用法(ChatModel)
ChatResponse response = chatModel.call(new Prompt("你好"));
// 高级用法(ChatClient)
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultSystem("你是恋爱顾问")
.build();
String response = chatClient.prompt().user("你好").call().content();
|
可以使用构造器方式或者建造者模式进行client的构造
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
// 方式1:使用构造器注入
@Service
public class ChatService {
private final ChatClient chatClient;
public ChatService(ChatClient.Builder builder) {
this.chatClient = builder
.defaultSystem("你是恋爱顾问")
.build();
}
}
// 方式2:使用建造者模式
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultSystem("你是恋爱顾问")
.build();
|
chatclient支持多种response的响应格式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
// ChatClient支持多种响应格式
// 1. 返回 ChatResponse 对象(包含元数据如 token 使用量)
ChatResponse chatResponse = chatClient.prompt()
.user("Tell me a joke")
.call()
.chatResponse();
// 2. 返回实体对象(自动将 AI 输出映射为 Java 对象)
// 2.1 返回单个实体
record ActorFilms(String actor, List<String> movies) {}
ActorFilms actorFilms = chatClient.prompt()
.user("Generate the filmography for a random actor.")
.call()
.entity(ActorFilms.class);
// 2.2 返回泛型集合
List<ActorFilms> multipleActors = chatClient.prompt()
.user("Generate filmography for Tom Hanks and Bill Murray.")
.call()
.entity(new ParameterizedTypeReference<List<ActorFilms>>() {});
// 3. 流式返回(适用于打字机效果)
Flux<String> streamResponse = chatClient.prompt()
.user("Tell me a story")
.stream()
.content();
// 也可以流式返回ChatResponse
Flux<ChatResponse> streamWithMetadata = chatClient.prompt()
.user("Tell me a story")
.stream()
.chatResponse();
|
值得关注的是结构化输出,springai可以直接将响应数据转换为java对象,还有流式输出,能更直观看到ai输出,优化用户体验
还有一个小点就是,client模式是支持提示词的动态更改的
1
2
3
4
5
6
7
8
9
10
11
|
// 定义默认系统提示词
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultSystem("You are a friendly chat bot that answers question in the voice of a {voice}")
.build();
// 对话时动态更改系统提示词的变量
chatClient.prompt()
.system(sp -> sp.param("voice", voice))
.user(message)
.call()
.content());
|
但我觉得,实际上springai框架相对于langchain4j来说,定制化是有差距的
Advisors
Spring AI 使用 Advisors(顾问)机制来增强 AI 的能力,可以理解为一系列可插拔的拦截器,在调用 AI 前和调用 AI 后可以执行一些额外的操作,比如:
- 前置增强:调用 AI 前改写一下 Prompt 提示词、检查一下提示词是否安全
- 后置增强:调用 AI 后记录一下日志、处理一下返回的结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
var chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(
new MessageChatMemoryAdvisor(chatMemory), // 对话记忆 advisor
new QuestionAnswerAdvisor(vectorStore) // RAG 检索增强 advisor
)
.build();
String response = this.chatClient.prompt()
// 对话时动态设定拦截器参数,比如指定对话记忆的 id 和长度
.advisors(advisor -> advisor.param("chat_memory_conversation_id", "678")
.param("chat_memory_response_size", 100))
.user(userText)
.call()
.content();
|
advisor是springai框架提供的一大核心功能, 持久化对话记忆,rag检索增强,这些都是用advisor来完成的
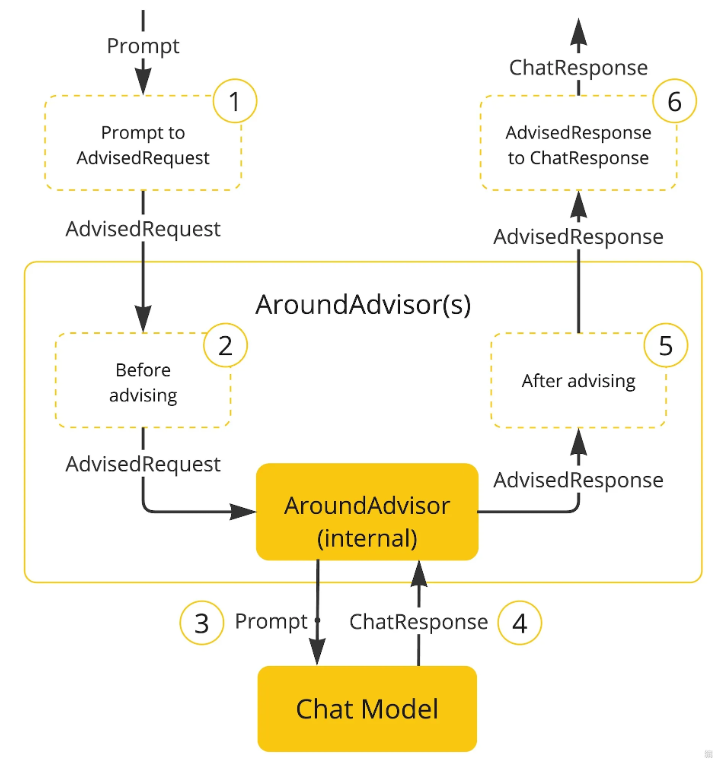
拦截器的执行顺序有getorder方法来决定
- 当你有多个 Advisor 时,通过实现
getOrder() 控制执行顺序
Ordered.HIGHEST_PRECEDENCE(最小)最先执行Ordered.LOWEST_PRECEDENCE(最大)最后执行
advisor支持流式和非流式两种模式,本质上其实没有区别,无非就是返回值不同,
流式方法是对数据直接进行处理,非流式方法,则是在数据流传输上下游对数据进行处理
实现多轮对话
使用Chat memory advisor拦截器,可以实现对话的记忆持久化
实现ChatMemory接口,可以自定义实现会话的获取,存储
在调用对话方法的时候,指定获取历史对话的条数
自定义的advisor
可以通过实现callaroudadvisor接口和streamAroundadvisor方法来实现自定义的advisor
一个是流式,一个是非流式,通过实现自定义的advisor,来对请求前后的数据进行方法增强
例如日志文件拦截器,对用户调用方法前后数据进行日志输出打印
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
|
/**
* 自定义日志 Advisor
* 打印 info 级别日志、只输出单次用户提示词和 AI 回复的文本
*
* 功能说明:
* 1. 在调用 AI 前记录用户输入的提示词
* 2. 在 AI 返回响应后记录生成的文本内容
* 3. 同时支持同步调用和流式调用两种场景
*/
@Slf4j
public class MyLoggerAdvisor implements CallAroundAdvisor, StreamAroundAdvisor {
/**
* 获取 Advisor 的名称,用于标识和调试
* @return 返回当前类的简单类名作为顾问名称
*/
@Override
public String getName() {
return this.getClass().getSimpleName();
}
/**
* 获取 Advisor 的执行顺序
* 返回值越小,优先级越高,越先执行
* @return 返回 0,表示较高优先级
*/
@Override
public int getOrder() {
return 0;
}
/**
* 前置处理方法:在调用 AI 之前执行
*
* @param request 原始的请求对象
* @return 处理后的请求对象(可能被修改)
*/
private AdvisedRequest before(AdvisedRequest request) {
// 记录用户输入的文本内容
// userText() 方法会获取用户输入的提示词
log.info("AI Request: {}", request.userText());
return request;
}
/**
* 后置观察方法:在 AI 返回响应后执行
* 用于记录 AI 生成的完整文本内容
*
* @param advisedResponse AI 返回的响应对象
*/
private void observeAfter(AdvisedResponse advisedResponse) {
// 从响应对象中提取 AI 生成的文本内容并记录日志
// 调用链:response -> 获取结果 -> 获取输出 -> 获取文本
log.info("AI Response: {}", advisedResponse.response().getResult().getOutput().getText());
}
/**
* 同步调用的环绕增强方法
* 适用于非流式场景,AI 一次性返回完整响应
*
* @param advisedRequest 请求对象
* @param chain 顾问链,用于调用下一个顾问或最终的 AI 模型
* @return AI 返回的响应对象
*/
@Override
public AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {
// 1. 前置处理:记录请求日志
advisedRequest = this.before(advisedRequest);
// 2. 调用链中的下一个组件(可能是另一个顾问,最终是 AI 模型)
AdvisedResponse advisedResponse = chain.nextAroundCall(advisedRequest);
// 3. 后置处理:记录响应日志
this.observeAfter(advisedResponse);
// 4. 返回响应给调用方
return advisedResponse;
}
/**
* 流式调用的环绕增强方法
* 适用于流式场景,AI 分批次返回响应片段(Flux 流)
*
* 实现原理:
* 1. 先执行前置处理记录请求日志
* 2. 获取 AI 返回的响应流(多个片段)
* 3. 使用 MessageAggregator 将流式片段聚合成完整响应
* 4. 在聚合完成后(即所有片段接收完毕),执行后置处理记录完整日志
*
* 注意:使用聚合器意味着会等待所有响应片段接收完毕才执行 observeAfter
* 这保证了日志记录的完整性,但会牺牲首字延迟的优势
*
* @param advisedRequest 请求对象
* @param chain 顾问链,用于调用下一个顾问或最终的 AI 模型
* @return 响应流(Flux 类型,包含多个响应片段)
*/
@Override
public Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {
// 1. 前置处理:记录请求日志(与同步调用共享相同的前置逻辑)
advisedRequest = this.before(advisedRequest);
// 2. 获取 AI 返回的响应流(尚未真正执行)
Flux<AdvisedResponse> advisedResponses = chain.nextAroundStream(advisedRequest);
// 3. 使用 MessageAggregator 聚合响应流
// aggregateAdvisedResponse 会等待所有响应片段接收完毕
// 然后调用 observeAfter 记录完整的 AI 响应内容
// 最后将聚合后的响应重新封装为 Flux 流返回
return (new MessageAggregator()).aggregateAdvisedResponse(advisedResponses, this::observeAfter);
}
}
|
结构化输出
结构化输出转换器,是springai框架中的一种机制,将大模型返回的文本数据进行数据结构化,可以结构化为json,xml,或者java类
他的原理是,在调用大模型之前,对提示词先进行增强,增加一段提示词,让大模型以要求的数据格式返回数据,然后在接受到大模型返回的数据之后,又将文本转换为要求的数据格式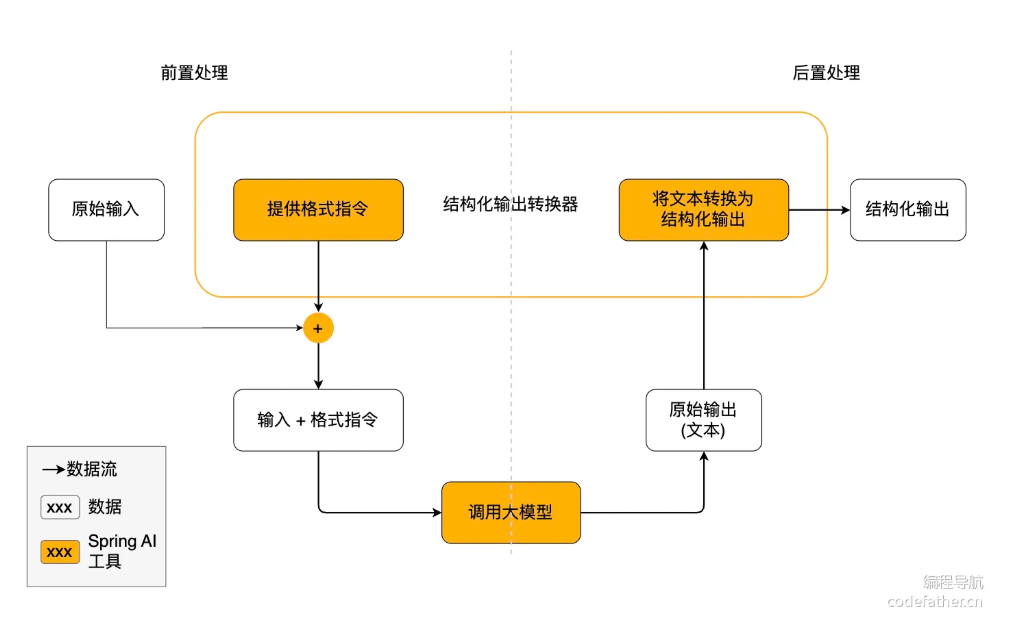
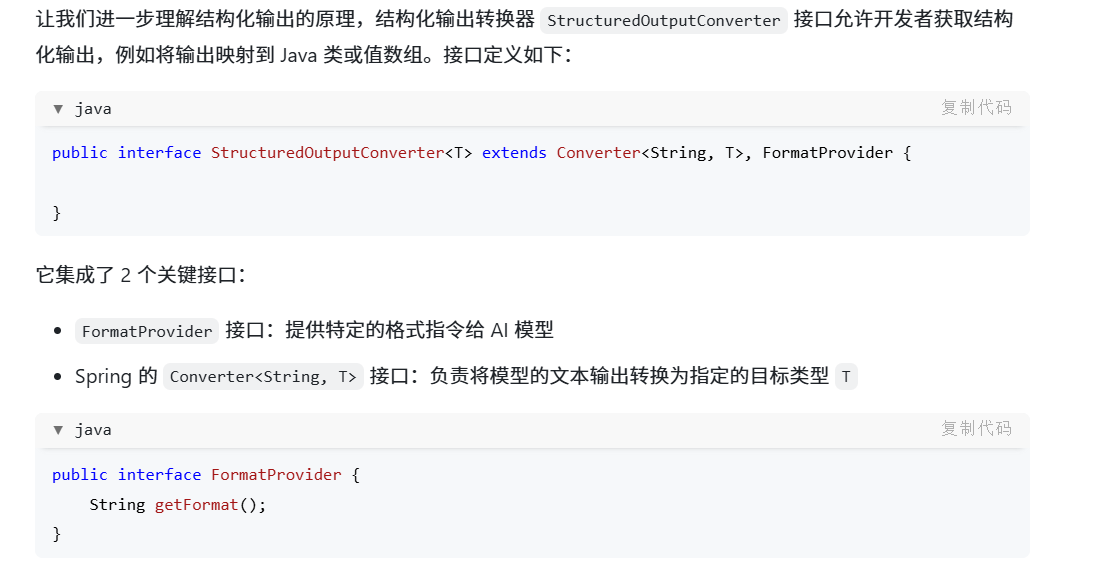
Spring AI 输出转换器
Spring AI 提供了多种转换器实现,分别用于将输出转换为不同的结构:
-
AbstractConversionServiceOutputConverter:提供预配置的 GenericConversionService,用于将 LLM 输出转换为所需格式
-
AbstractMessageOutputConverter:支持 Spring AI Message 的转换
-
BeanOutputConverter:用于将输出转换为 Java Bean 对象(基于 ObjectMapper 实现)
-
MapOutputConverter:用于将输出转换为 Map 结构
-
ListOutputConverter:用于将输出转换为 List 结构
对话记忆持久化
对话记忆的持久化,可以保存到文件,数据库,redis或者其他对象存储中
项目中使用的是自定义文件持久化,但是因为message类型多种多样,用json进行序列化比较困难,所以引入kryo序列化库
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
/**
* 基于文件持久化的对话记忆
*/
public class FileBasedChatMemory implements ChatMemory {
private final String BASE_DIR;
private static final Kryo kryo = new Kryo();
static {
kryo.setRegistrationRequired(false);
// 设置实例化策略
kryo.setInstantiatorStrategy(new StdInstantiatorStrategy());
}
// 构造对象时,指定文件保存目录
public FileBasedChatMemory(String dir) {
this.BASE_DIR = dir;
File baseDir = new File(dir);
if (!baseDir.exists()) {
baseDir.mkdirs();
}
}
@Override
public void add(String conversationId, List<Message> messages) {
List<Message> conversationMessages = getOrCreateConversation(conversationId);
conversationMessages.addAll(messages);
saveConversation(conversationId, conversationMessages);
}
@Override
public List<Message> get(String conversationId, int lastN) {
List<Message> allMessages = getOrCreateConversation(conversationId);
return allMessages.stream()
.skip(Math.max(0, allMessages.size() - lastN))
.toList();
}
@Override
public void clear(String conversationId) {
File file = getConversationFile(conversationId);
if (file.exists()) {
file.delete();
}
}
private List<Message> getOrCreateConversation(String conversationId) {
File file = getConversationFile(conversationId);
List<Message> messages = new ArrayList<>();
if (file.exists()) {
try (Input input = new Input(new FileInputStream(file))) {
messages = kryo.readObject(input, ArrayList.class);
} catch (IOException e) {
e.printStackTrace();
}
}
return messages;
}
private void saveConversation(String conversationId, List<Message> messages) {
File file = getConversationFile(conversationId);
try (Output output = new Output(new FileOutputStream(file))) {
kryo.writeObject(output, messages);
} catch (IOException e) {
e.printStackTrace();
}
}
private File getConversationFile(String conversationId) {
return new File(BASE_DIR, conversationId + ".kryo");
}
}
|
基于springai提供的inmemoryChatmemory类的构造思路,自定义一个chatmemory,实现增删改查的功能,自定义文件持久化
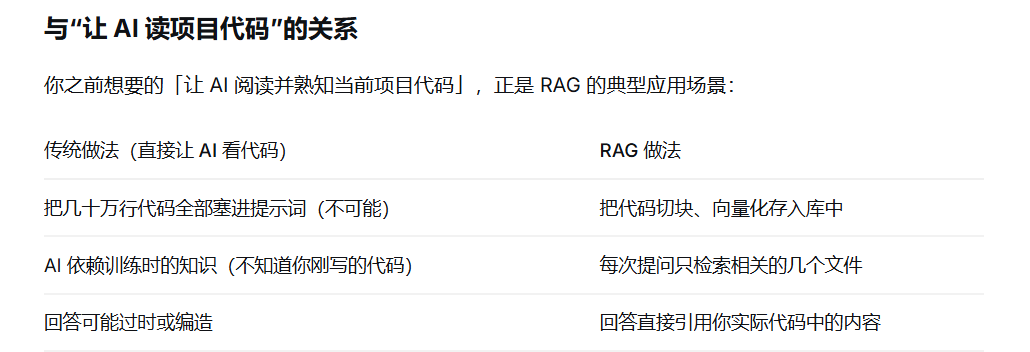
RAG
RAG本质上是一种结合信息检索技术和AI内容生成的混合架构,Retrieval(检索)、Augmented(增强)、Generation(生成)
首先会对用户的问题进行向量化,转换为数学上的向量表示
然后第一步,进行检索
召回:根据用户输入的查询(Query),从大规模知识库中快速、准确地找到最相关的若干文档片段(通常称为Top-K个片段)。
通过内部或者外部,已经构建好的向量知识库中,获取到最相似最接近的文档片段
精排和rank模型:通过rank模型对于召回的数据进行权重排序,取出top数据
混合检索策略:
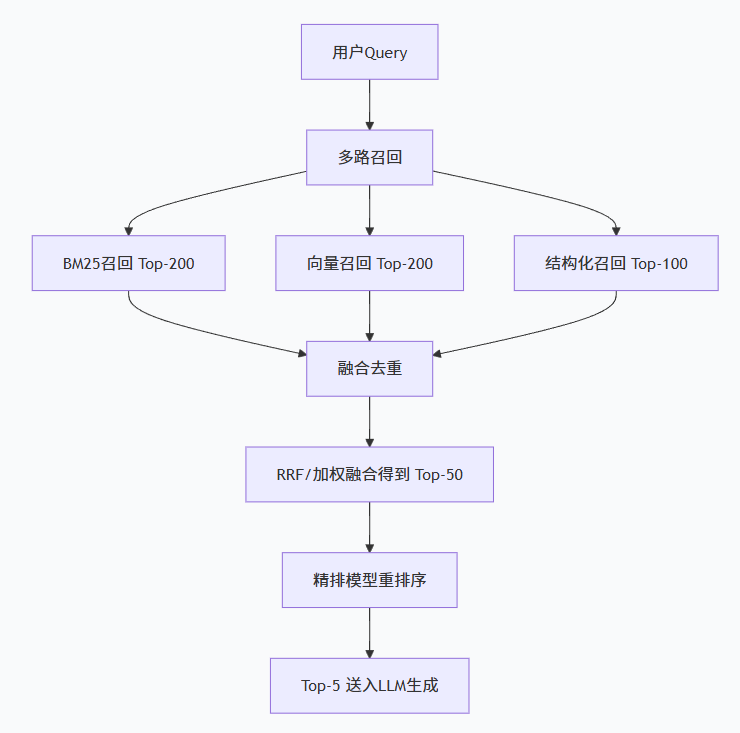
第二部,进行增强
将获取到的文档资料,与用户问题进行拼接,获得一个更完整的promat,补充大模型不知道的知识(向量数据库中的知识)
第三步,进行内容生成
让大模型可以依据向量数据库中的知识,对于用户问题进行一个更好的回答
在天门山智能助手这个项目中,使用到的向量数据库是springai提供的一个基于内存的向量数据库,VectorStore,将本地文件加载到向量数据库中,进行检索
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
package com.ai.bryanagent.rag;
import jakarta.annotation.Resource;
import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.List;
/**
* LoveAppVectorStoreConfig 类用于配置向量存储
* 该类负责创建和配置向量存储Bean,用于文档的向量化存储和检索
*/
@Configuration
public class LoveAppVectorStoreConfig {
@Resource
private LoveAppDocumentLoader loveAppDocumentLoader;
/**
* 创建并配置向量存储Bean
*
* @param dashscopeEmbeddingModel 阿里云Dashscope的嵌入模型,用于文本向量化
* @return 配置好的VectorStore实例,可用于文档的存储和检索
*/
@Bean
VectorStore loveAppVectorStore(EmbeddingModel dashscopeEmbeddingModel) {
// 创建SimpleVectorStore实例,使用指定的嵌入模型
SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(dashscopeEmbeddingModel)
.build();
// 加载文档
List<Document> documents = loveAppDocumentLoader.loadMarkdowns();
simpleVectorStore.add(documents);
return simpleVectorStore;
}
}
|

RAG的核心特性
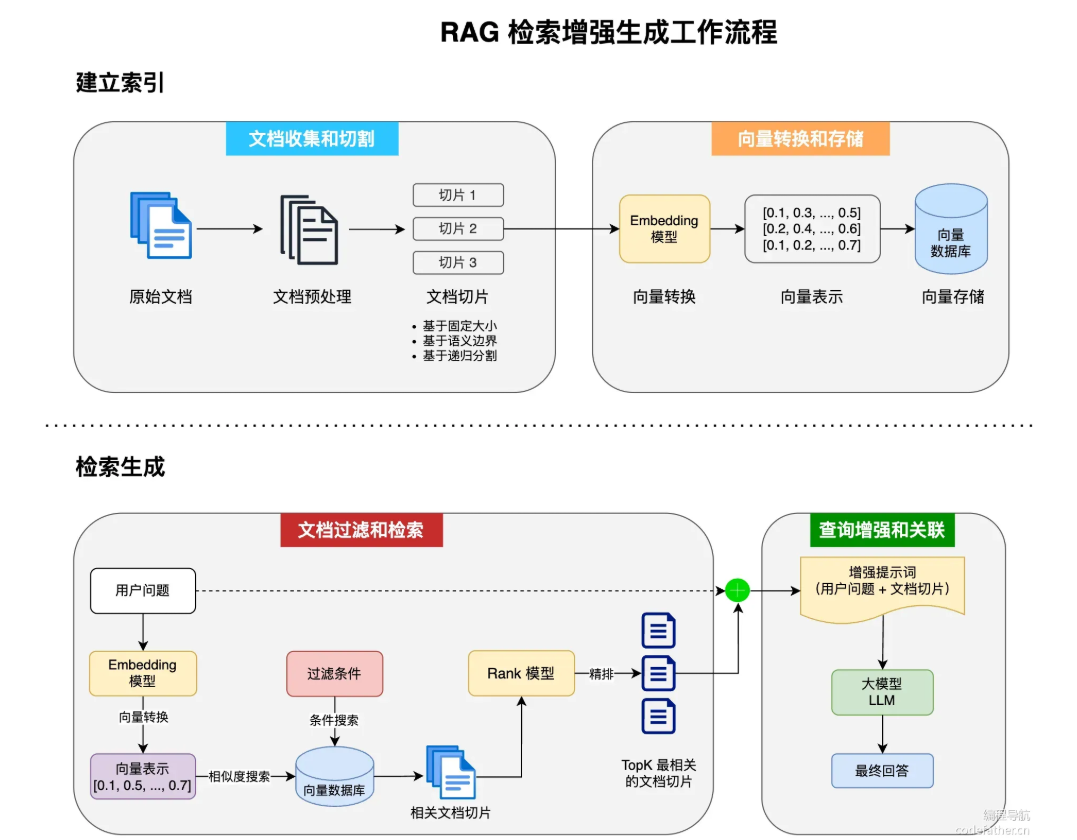
文档的切割和收集-ETL
文档收集和切割阶段,我们要对自己准备好的知识库文档进行处理,然后保存到向量数据库中。这个过程俗称 ETL(抽取、转换、加载)
在 Spring AI 中,对 Document 的处理通常遵循以下流程:
- 读取文档:使用 DocumentReader 组件从数据源(如本地文件、网络资源、数据库等)加载文档。
- 转换文档:根据需求将文档转换为适合后续处理的格式,比如去除冗余信息、分词、词性标注等,可以使用 DocumentTransformer 组件实现。
- 写入文档:使用 DocumentWriter 将文档以特定格式保存到存储中,比如将文档以嵌入向量的形式写入到向量数据库,或者以键值对字符串的形式保存到 Redis 等 KV 存储中。
向量转换和存储
在springai中,主要是通过VectorStore这个组件来实现文档数据的向量存储,他提供了一个VectorStore接口和向量存储整合包,帮助开发者简化了数据转换和存储的业务,实现快速整合
将文档数组转换为一个List ,然后交给内嵌模型去进行向量转换,向量转换完成之后,进行向量的存储
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public interface VectorStore extends DocumentWriter {
default String getName() {
return this.getClass().getSimpleName();
}
void add(List<Document> documents);
void delete(List<String> idList);
void delete(Filter.Expression filterExpression);
default void delete(String filterExpression) { ... };
List<Document> similaritySearch(String query);
List<Document> similaritySearch(SearchRequest request);
default <T> Optional<T> getNativeClient() {
return Optional.empty();
}
}
|
1
2
3
4
5
6
7
8
|
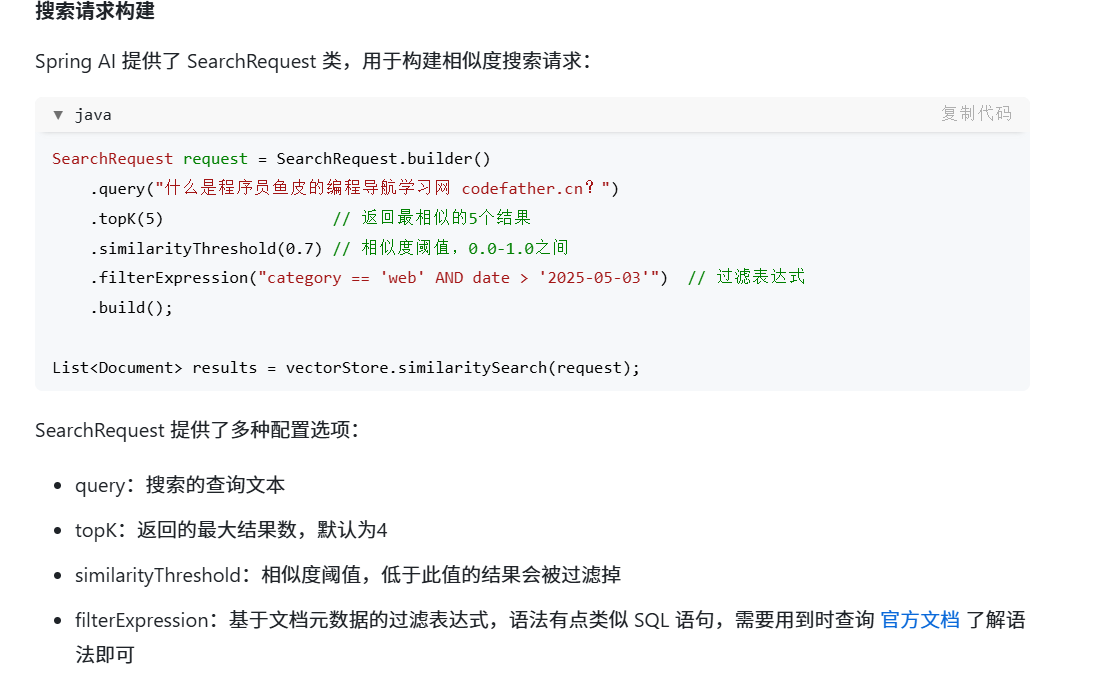
SearchRequest request = SearchRequest.builder()
.query("什么是程序员鱼皮的编程导航学习网 codefather.cn?")
.topK(5) // 返回最相似的5个结果
.similarityThreshold(0.7) // 相似度阈值,0.0-1.0之间
.filterExpression("category == 'web' AND date > '2025-05-03'") // 过滤表达式
.build();
List<Document> results = vectorStore.similaritySearch(request);
|
扩展知识 - 批处理策略
在使用向量存储时,可能要嵌入大量文档,如果一次性处理存储大量文档,可能会导致性能问题、甚至出现错误导致数据不完整。
举个例子,嵌入模型一般有一个最大标记限制,通常称为上下文窗口大小(context window size),限制了单个嵌入请求中可以处理的文本量。如果在一次调用中转换过多文档可能直接导致报错。
为此,Spring AI 实现了批处理策略(Batching Strategy),将大量文档分解为较小的批次,使其适合嵌入模型的更大上下文窗口,还可以提高性能并更有效地利用 API 速率限制。
Spring AI 通过 BatchingStrategy 接口提供该功能,该接口允许基于文档的标记计数并以分批方式处理文档:
public interface BatchingStrategy {
List<List> batch(List documents);
}
该接口定义了一个单一方法 batch,它接收一个文档列表并返回一个文档批次列表。
Spring AI 提供了一个名为 TokenCountBatchingStrategy 的默认实现。这个策略为每个文档估算 token 数,将文档分组到不超过最大输入 token 数的批次中,如果单个文档超过此限制,则抛出异常。这样就确保了每个批次不超过计算出的最大输入 token 数。
| 组件 |
说明 |
| 解决的问题 |
大量文档一次性嵌入会导致超限、报错、性能差 |
| 根本原因 |
嵌入模型的上下文窗口(token 限制) |
| 解决方案 |
批处理策略(Batching Strategy) |
| 核心接口 |
BatchingStrategy,只有一个 batch() 方法 |
| 默认实现 |
TokenCountBatchingStrategy:按 token 数分批,超限文档抛异常 |
将文档拆分, 进行批量处理
文档过滤和检索
Spring AI 官方声称提供了一个“模块化”的 RAG 架构,用于优化大模型回复的准确性。
简单来说,就是把整个文档过滤检索阶段拆分为:检索前、检索时、检索后,分别针对每个阶段提供了可自定义的组件。
- 在预检索阶段,系统接收用户的原始查询,通过查询转换和查询扩展等方法对其进行优化,输出增强的用户查询。
- 在检索阶段,系统使用增强的查询从知识库中搜索相关文档,可能涉及多个检索源的合并,最终输出一组相关文档。
- 在检索后阶段,系统对检索到的文档进行进一步处理,包括排序、选择最相关的子集以及压缩文档内容,输出经过优化的相关文档集。
查询增强和关联
1.QuestionAnswerAdvisor — 查询增强
| 属性 |
说明 |
| 所属阶段 |
预检索阶段(Pre-Retrieval) |
| 核心作用 |
将用户问题与检索到的文档组合成提示词(Prompt),引导大模型基于文档回答 |
| 工作方式 |
采用“问题-上下文”模板,将用户查询和检索到的相关文档拼接后送入大模型 |
| 典型场景 |
简单的 QA 场景,不涉及复杂查询改写,仅做基础的内容增强 |
代码示例:
java
1
2
3
|
QuestionAnswerAdvisor advisor = QuestionAnswerAdvisor.builder()
.chatModel(chatModel)
.build();
|
2.RetrievalAugmentationAdvisor — 查询增强
| 属性 |
说明 |
| 所属阶段 |
全流程(预检索 → 检索 → 检索后) |
| 核心作用 |
提供完整的、模块化的 RAG 增强能力,包括查询转换、多源检索、结果重排序等 |
| 工作方式 |
通过可插拔组件(QueryTransformer、DocumentRetriever、DocumentPostProcessor)灵活配置每个阶段 |
| 典型场景 |
复杂 RAG 应用,需要对查询改写、相似度阈值、检索后处理进行精细控制 |
代码示例:
java
1
2
3
4
5
|
RetrievalAugmentationAdvisor advisor = RetrievalAugmentationAdvisor.builder()
.queryTransformers(rewriteQueryTransformer)
.documentRetriever(vectorStoreRetriever)
.documentPostProcessors(compressionPostProcessor)
.build();
|
3.ContextualQueryAugmenter — 空上下文处理
| 属性 |
说明 |
| 所属阶段 |
预检索阶段 / 对话上下文管理 |
| 核心作用 |
处理多轮对话中的空上下文或指代不明确的问题(如“它的原理是什么?”中的“它”) |
| 工作方式 |
分析当前查询与历史对话记录的关联,自动补充缺失的实体或上下文信息,生成完整的独立查询 |
| 典型场景 |
多轮对话 RAG、需要维护对话状态的智能客服 |
代码示例:
java
1
2
3
4
5
6
7
8
9
|
ContextualQueryAugmenter augmenter = ContextualQueryAugmenter.builder()
.chatModel(chatModel)
.build();
String augmentedQuery = augmenter.augment(
"它的原理是什么?",
historyConversation
);
// 输出: "RAG 技术的原理是什么?"(假设历史中提到了 RAG)
|
快速对比表
| 维度 |
QuestionAnswerAdvisor |
RetrievalAugmentationAdvisor |
ContextualQueryAugmenter |
| 核心职责 |
基础问答增强 |
完整 RAG 流水线 |
多轮对话上下文补全 |
| 是否可定制 |
❌ 低 |
✅ 高(组件化) |
⚠️ 中(依赖 ChatModel) |
| 查询改写能力 |
❌ 无 |
✅ 有(通过 QueryTransformer) |
✅ 有(基于历史) |
| 检索后处理 |
❌ 无 |
✅ 有(排序/压缩) |
❌ 无 |
| 适用场景 |
单轮、简单问答 |
复杂、生产级 RAG |
多轮、需记忆对话 |
总结一句话
- QuestionAnswerAdvisor:做“检索内容 + 问题”的基础拼装。
- RetrievalAugmentationAdvisor:做端到端的、可插拔的 RAG 全流程增强。
- ContextualQueryAugmenter:做多轮对话中的“补全指代、消除歧义”。
RAG调优
文档的切割与收集
优化原始文档
将文档内容结构化,规范化,格式标准化

在保证知识完备性的情况下,优化初始原档,优化原始文档的好处就是,对于后续的检索精确度更高。
文档切片
合适的切片大小和切片方式,对于文档的检索至关重要
一般有几种方法来对文档进行切片,固定大小切片,根据语义切片,使用ai大模型对文档进行切片
我们需要保证的几个点是:
不能让文本切片过短,如果过短,那么可能会有语义确实的问题,在检索时,会丢失关键数据
不能让文本切片过长,如果过长,在召回时,可能会返回很多与关键词无关的信息
不能出现明显的语义阶段,导致召回时,出现数据不完整的情况,导致语义不符合要求,数据精确度低
在编程实现上,可以使用spring ai提供的DocumentTransformer接口来完成文档的切片
DocumentTransformer 的主要实现类
Spring AI 提供了多种内置的 DocumentTransformer 实现,满足不同场景的转换需求:
| 实现类 |
类型 |
核心功能 |
底层依赖 |
| TokenTextSplitter |
文本切分 |
按 Token 数量切分文档 |
CL100K_BASE 编码 |
| ContentFormatTransformer |
格式转换 |
统一文档元数据格式 |
模板配置 |
| KeywordMetadataEnricher |
元数据增强 |
AI 提取关键词并添加到元数据 |
ChatModel |
| SummaryMetadataEnricher |
元数据增强 |
AI 生成文档摘要并添加到元数据 |
ChatModel |
示例代码
1
2
3
4
5
6
7
8
9
10
11
12
|
@Component
class MyTokenTextSplitter {
public List<Document> splitDocuments(List<Document> documents) {
TokenTextSplitter splitter = new TokenTextSplitter();
return splitter.apply(documents);
}
public List<Document> splitCustomized(List<Document> documents) {
TokenTextSplitter splitter = new TokenTextSplitter(200, 100, 10, 5000, true);
return splitter.apply(documents);
}
}
|
| 序号 |
参数名 |
传入值 |
含义 |
影响 |
| ① |
defaultChunkSize |
200 |
目标块大小(Token 数) |
每个 Document 块约 200 tokens |
| ② |
minChunkSize |
100 |
最小块大小 |
切出的块如果 <100 tokens,会尝试与相邻块合并 |
| ③ |
overlapTokens |
10 |
相邻块重叠 Token 数 |
每个新块会重复前一块的最后 10 个 token |
| ④ |
maxChunkSize |
5000 |
单块绝对上限 |
单个块不会超过 5000 tokens(保护 LLM 上下文) |
| ⑤ |
ensureOverlap |
true |
强制保证重叠 |
即使文档很短也会尽量维持重叠(通常配合小文档使用) |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
@Resource
private MyTokenTextSplitter myTokenTextSplitter;
@Bean
VectorStore loveAppVectorStore(EmbeddingModel dashscopeEmbeddingModel) {
SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(dashscopeEmbeddingModel)
.build();
// 加载文档
List<Document> documents = loveAppDocumentLoader.loadMarkdowns();
// 自主切分
List<Document> splitDocuments = myTokenTextSplitter.splitCustomized(documents);
simpleVectorStore.add(splitDocuments);
return simpleVectorStore;
}
|
元数据的标注
元数据实际上本质就是一个map,为文档提供一个结构化的数据标注,便于后续的向量化处理和精准检索
例如
1
2
3
4
5
6
|
Map.of(
"type", "interior", // 文档类型
"year", "2025", // 年份
"month", "05", // 月份
"style", "modern", // 装修风格
);
|
DocumentTransformer里面有一个组件叫做KeywordMetadataEnricher,可以使用ai对document进行自动解析关键词,并添加到元数据中
示例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
@Component
class MyKeywordEnricher {
@Resource
private ChatModel dashscopeChatModel;
List<Document> enrichDocuments(List<Document> documents) {
KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(this.dashscopeChatModel, 5);
return enricher.apply(documents);
}
}
@Bean
VectorStore loveAppVectorStore(EmbeddingModel dashscopeEmbeddingModel) {
SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(dashscopeEmbeddingModel)
.build();
// 加载文档
List<Document> documents = loveAppDocumentLoader.loadMarkdowns();
// 自动补充关键词元信息
List<Document> enrichedDocuments = myKeywordEnricher.enrichDocuments(documents);
simpleVectorStore.add(enrichedDocuments);
return simpleVectorStore;
}
|
向量转换和存储
向量的转换和存储是rag中至关重要的一步,在springai中,提供了一个VctorStore接口来统一管理,先使用嵌入模型,将文档转换为向量,然后存储到向量数据库中,最重要的就是一个技术选型,在考虑成本的情况下,选择一个效果好的模型,因为向量转换,直接涉及到了后面的召回,数据权重计算多个步骤,是实实在在影响检索和提示词增强的
文档过滤和检索
首先是多查询拓展,顾名思义,就是进行多个查询,因为有可能用户的提示词不够准确,导致结果不够完整,先将用户提示词交给ai,并生成多个增强后的提示词,然后使用多个提示词去向量库进行检索,获得多个文档检索结果,在去重合并精排之后,获得到的就是较完整的文档数据,理论上来说,ai输出的内容也会更全面,更完善
但因为多次查询,对于ai的token消耗也会更多,如果对于提示词增强和拓展过多,也会导致结果不精准的问题,其实这个方式不是最好的
示例代码
1
2
3
4
5
|
MultiQueryExpander queryExpander = MultiQueryExpander.builder()
.chatClientBuilder(chatClientBuilder)
.numberOfQueries(3)
.build();
List<Query> queries = queryExpander.expand(new Query("谁是程序员啊?"));
|
1
2
3
4
5
6
7
8
9
10
11
12
|
DocumentRetriever retriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.similarityThreshold(0.73)
.topK(5)
.filterExpression(new FilterExpressionBuilder()
.eq("genre", "fairytale")
.build())
.build();
// 直接用扩展后的查询来获取文档
List<Document> retrievedDocuments = documentRetriever.retrieve(query);
// 输出扩展后的查询文本
System.out.println(query.text());
|
第二种方式就是查询重写,springai提供了一个queryTransformer,查询重写转换器,将用户提示词交给ai,进行一个提示词的增强
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
@Component
public class QueryRewriter {
private final QueryTransformer queryTransformer;
public QueryRewriter(ChatModel dashscopeChatModel) {
ChatClient.Builder builder = ChatClient.builder(dashscopeChatModel);
// 创建查询重写转换器
queryTransformer = RewriteQueryTransformer.builder()
.chatClientBuilder(builder)
.build();
}
public String doQueryRewrite(String prompt) {
Query query = new Query(prompt);
// 执行查询重写
Query transformedQuery = queryTransformer.transform(query);
// 输出重写后的查询
return transformedQuery.text();
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
@Resource
private QueryRewriter queryRewriter;
public String doChatWithRag(String message, String chatId) {
// 查询重写
String rewrittenMessage = queryRewriter.doQueryRewrite(message);
ChatResponse chatResponse = chatClient
.prompt()
.user(rewrittenMessage)
.call()
.chatResponse();
String content = chatResponse.getResult().getOutput().getText();
return content;
}
|
检索器配置
通过设置阈值,过滤掉相似度不够的文档
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
@Slf4j
public class LoveAppRagCustomAdvisorFactory {
public static Advisor createLoveAppRagCustomAdvisor(VectorStore vectorStore, String status) {
Filter.Expression expression = new FilterExpressionBuilder()
.eq("status", status)
.build();
DocumentRetriever documentRetriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.filterExpression(expression) // 过滤条件
.similarityThreshold(0.5) // 相似度阈值
.topK(3) // 返回文档数量
.build();
return RetrievalAugmentationAdvisor.builder()
.documentRetriever(documentRetriever)
.build();
}
}
|
也可以设置过滤条件,比如元数据中的字段,如果文档不包含字段,那么就不会被召回,也可以设置返回的文档数量
查询增强和关联
查询增强和关联,最重要的就是,向量库中并没有召回到用户提问的关联数据,此时上下文就是空的,也就是会有边界情况,这是我们可以根据业务情况对此类异常进行处理,如果在数据库中没有查询到相关文档,或者相似度过低,那么就自定义一段模板作为上下文,要不就是用提示词告诉ai,你不需要回答这个问题,就说你不知道,如果对于上下文为空没有要求,那么就将用户输入的提示词/增强后的用户提示词直接交给ai进行回答
边界情况处理可以使用 Spring AI 的 ContextualQueryAugmenter 上下文查询增强器:
1
2
3
4
5
6
|
RetrievalAugmentationAdvisor.builder()
.queryAugmenter(
ContextualQueryAugmenter.builder()
.allowEmptyContext(false)
.build()
)
|
也可以使用自定义的ContextualQueryAugmenter
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public class LoveAppContextualQueryAugmenterFactory {
public static ContextualQueryAugmenter createInstance() {
PromptTemplate emptyContextPromptTemplate = new PromptTemplate("""
你应该输出下面的内容:
抱歉,我只能回答恋爱相关的问题,别的没办法帮到您哦,
有问题可以联系编程导航客服 https://codefather.cn
""");
return ContextualQueryAugmenter.builder()
.allowEmptyContext(false)
.emptyContextPromptTemplate(emptyContextPromptTemplate)
.build();
}
}
|
1
2
3
4
|
RetrievalAugmentationAdvisor.builder()
.documentRetriever(documentRetriever)
.queryAugmenter(LoveAppContextualQueryAugmenterFactory.createInstance())
.build();
|
工具调用
工具调用的原理,工具调用并不是将自己服务器上的工具代码交给AI去执行,而是告诉AI,我有这么一个工具,如果你需要使用这个工具,那么输出对应的工具名称和参数,有服务器本地去执行工具代码,代码执行的结果再交给AI,让他继续工作,如果代码执行失败,也可以加上重试机制,主要就是赋予AI一个他本身没有的能力

为什么要这样做?直接让AI去完成代码的执行不是更好吗?但是很关键的一点是安全性,AI是否调用API和接触系统资源,本质上是由后端服务程序去决定的,不能让大模型直接接触到我们服务器的资源
定义工具
定义一个工具样例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
public class ResourceDownloadTool {
@Tool(description = "Download a resource from a given URL")
public String downloadResource(@ToolParam(description = "URL of the resource to download") String url, @ToolParam(description = "Name of the file to save the downloaded resource") String fileName) {
String fileDir = FileConstant.FILE_SAVE_DIR + "/download";
String filePath = fileDir + "/" + fileName;
try {
// 创建目录
FileUtil.mkdir(fileDir);
// 使用 Hutool 的 downloadFile 方法下载资源
HttpUtil.downloadFile(url, new File(filePath));
return "Resource downloaded successfully to: " + filePath;
} catch (Exception e) {
return "Error downloading resource: " + e.getMessage();
}
}
}
|
集中注册工具样例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
@Configuration
public class ToolRegistration {
@Value("${search-api.api-key}")
private String searchApiKey;
@Bean
public ToolCallback[] allTools() {
FileOperationTool fileOperationTool = new FileOperationTool();
WebSearchTool webSearchTool = new WebSearchTool(searchApiKey);
WebScrapingTool webScrapingTool = new WebScrapingTool();
ResourceDownloadTool resourceDownloadTool = new ResourceDownloadTool();
TerminalOperationTool terminalOperationTool = new TerminalOperationTool();
PDFGenerationTool pdfGenerationTool = new PDFGenerationTool();
return ToolCallbacks.from(
fileOperationTool,
webSearchTool,
webScrapingTool,
resourceDownloadTool,
terminalOperationTool,
pdfGenerationTool
);
}
}
|
使用工具调用样例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
@Resource
private ToolCallback[] allTools;
public String doChatWithTools(String message, String chatId) {
ChatResponse response = chatClient
.prompt()
.user(message)
.advisors(spec -> spec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId)
.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 10))
// 开启日志,便于观察效果
.advisors(new MyLoggerAdvisor())
.tools(allTools)
.call()
.chatResponse();
String content = response.getResult().getOutput().getText();
log.info("content: {}", content);
return content;
}
|
工具进阶知识
AI是怎么知道如何去调用工具,以及知道调用所需的参数的呢?
核心在于TollCallback接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public interface ToolCallback {
/**
* Definition used by the AI model to determine when and how to call the tool.
*/
ToolDefinition getToolDefinition();
/**
* Metadata providing additional information on how to handle the tool.
*/
ToolMetadata getToolMetadata();
/**
* Execute tool with the given input and return the result to send back to the AI model.
*/
String call(String toolInput);
/**
* Execute tool with the given input and context, and return the result to send back to the AI model.
*/
String call(String toolInput, ToolContext tooContext);
}
|
这个接口中:
getToolDefinition() 提供了工具的基本定义,包括名称、描述和调用参数,这些信息会传递给 AI 模型,帮助模型了解什么时候应该调用这个工具、以及如何构造参数getToolMetadata() 提供了处理工具的附加信息,比如是否直接返回结果等控制选项- 两个
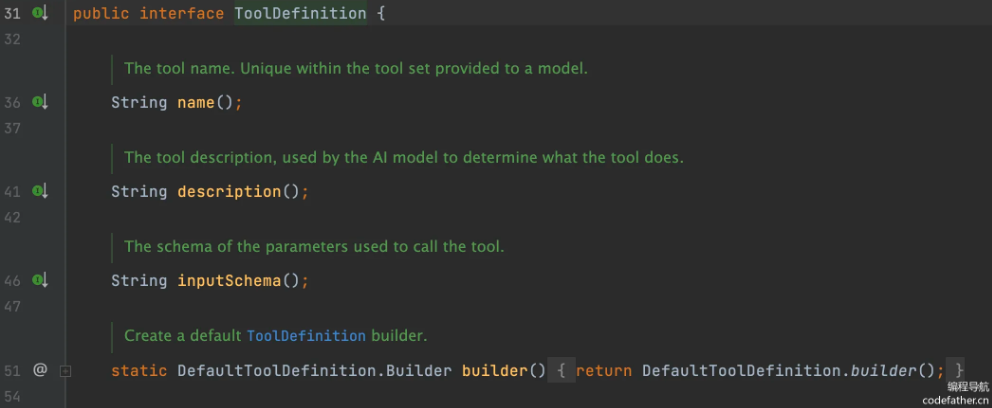
call() 方法是工具的执行入口,分别支持有上下文和无上下文的调用场景
工具定义类 ToolDefinition 的结构如下图,包含名称、描述和调用工具的参数。
可以使用构造器自定义一个工具定义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
public class WeatherToolDefinition {
/**
* 构建天气查询工具的定义
*/
public static ToolDefinition createWeatherTool() {
// 构建工具定义
ToolDefinition toolDefinition = ToolDefinition.builder()
// 工具名称
.name("currentWeather")
// 工具功能描述
.description("Get the weather in location")
// 入参规则(JSON Schema)
.inputSchema("""
{
"type": "object",
"properties": {
"location": {
"type": "string"
},
"unit": {
"type": "string",
"enum": ["C", "F"]
}
},
"required": ["location", "unit"]
}
""")
.build();
return toolDefinition;
}
}
|
但为什么我们刚刚定义工具时,直接通过注解就能把方法变成工具呢?
这是因为,当使用注解定义工具时,Spring AI 会做大量幕后工作:
JsonSchemaGenerator 会解析方法签名和注解,自动生成符合 JSON Schema 规范的参数定义,作为 ToolDefinition 的一部分提供给 AI 大模型ToolCallResultConverter 负责将各种类型的方法返回值统一转换为字符串,便于传递给 AI 大模型处理MethodToolCallback 实现了对注解方法的封装,使其符合 ToolCallback 接口规范
这种设计使我们可以专注于业务逻辑实现,无需关心底层通信和参数转换的复杂细节。如果需要更精细的控制,我们可以自定义 ToolCallResultConverter 来实现特定的转换逻辑,例如对某些特殊对象的自定义序列化。
工具上下文
在实际应用中工具调用可能会用到额外的上下文信息,比如登录用户信息,这时候springai提供了 一个toolcontex,本质上其实就是一个map,使用Treadlocal来存储,线程之间隔离,不会有线程安全的问题,在调用大模型的时候,传递上下文参数
1
2
3
4
5
6
7
8
9
10
11
|
// 从已登录用户中获取用户名称
String loginUserName = getLoginUserName();
String response = chatClient
.prompt("帮我查询用户信息")
.tools(new CustomerTools())
.toolContext(Map.of("userName", "yupi"))
.call()
.content();
System.out.println(response);
|
这种方式完全隔离了ai对于用户信息的获取,是比较安全的做法,同时springai在请求结束之后,会将Treadloacl给remove,所以也不会有oom的问题
使用上下文参数样例代码
1
2
3
4
5
6
7
8
|
class CustomerTools {
@Tool(description = "Retrieve customer information")
Customer getCustomerInfo(Long id, ToolContext toolContext) {
return customerRepository.findById(id, toolContext.getContext().get("userName"));
}
}
|
立即返回
在调用工具之后,有些场景是不需要将工具调用的结果返回给大模型的,而是直接返回给用户,比如生成pdf这种工具调用,生成之后应该直接返回给用户,springai通过returndirect这个属性控制是否直接返回,将其设置为true的话,会直接更改工具调用的基本流程,工具调用完之后直接返回给用户,有意思的是,这个属性是放在工具的元数据中的,不会作为提示词传入到大模型,工具调用完之后,结果直接返回给用户
如何启用这个方法,如果使用注解编程,直接指定returndirect参数就行
1
2
3
4
5
6
|
class CustomerTools {
@Tool(description = "Retrieve customer information", returnDirect = true)
Customer getCustomerInfo(Long id) {
return customerRepository.findById(id);
}
}
|
如果是使用编程方式手动注册一个tool的话
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// 设置元数据包含 returnDirect 属性
ToolMetadata toolMetadata = ToolMetadata.builder()
.returnDirect(true)
.build();
Method method = ReflectionUtils.findMethod(CustomerTools.class, "getCustomerInfo", Long.class);
ToolCallback toolCallback = MethodToolCallback.builder()
.toolDefinition(ToolDefinition.builder(method)
.description("Retrieve customer information")
.build())
.toolMethod(method)
.toolObject(new CustomerTools())
.toolMetadata(toolMetadata)
.build();
|
工具底层执行原理
Spring AI 提供了两种工具执行模式:框架控制的工具执行和用户控制的工具执行。这两种模式都离不开一个核心组ToolCallingManager。
ToolCallingManager 接口可以说是 Spring AI 工具调用中最值得学习的类了。它是管理 AI 工具调用全过程的核心组件,负责根据 AI 模型的响应执行对应的工具并返回执行结果给大模型。此外,它还支持异常处理,可以统一处理工具执行过程中的错误情况。
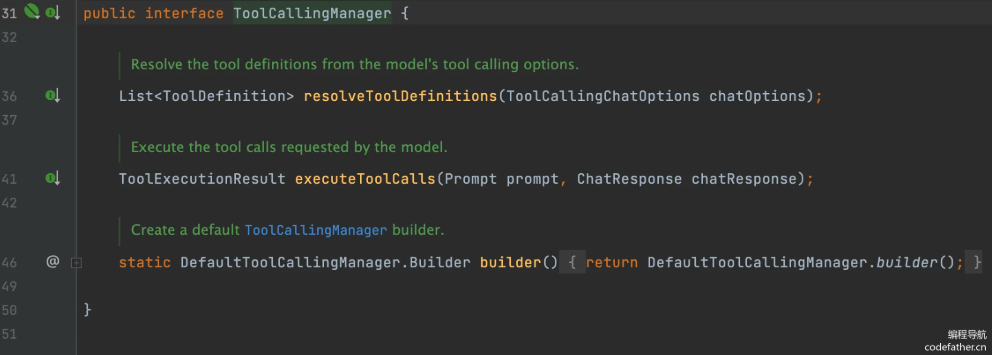
其中的 2 个核心方法:
resolveToolDefinitions:从模型的工具调用选项中解析工具定义executeToolCalls:执行模型请求对应的工具调用
如果你使用的是任何 Spring AI 相关的 Spring Boot Starter,都会默认初始化一个 DefaultToolCallingManager。
如果不想用默认的,也可以自己定义 ToolCallingManager Bean。
1
2
3
4
|
@Bean
ToolCallingManager toolCallingManager() {
return ToolCallingManager.builder().build();
}
|
ToolCallingManager 怎么知道是否要调用工具呢?
由于这块的实现可能会更新,建议大家学会看源码来分析,比如查看执行工具调用的源码,会发现它其实是从 AI 返回的 toolCalls 参数中获取要调用的工具:
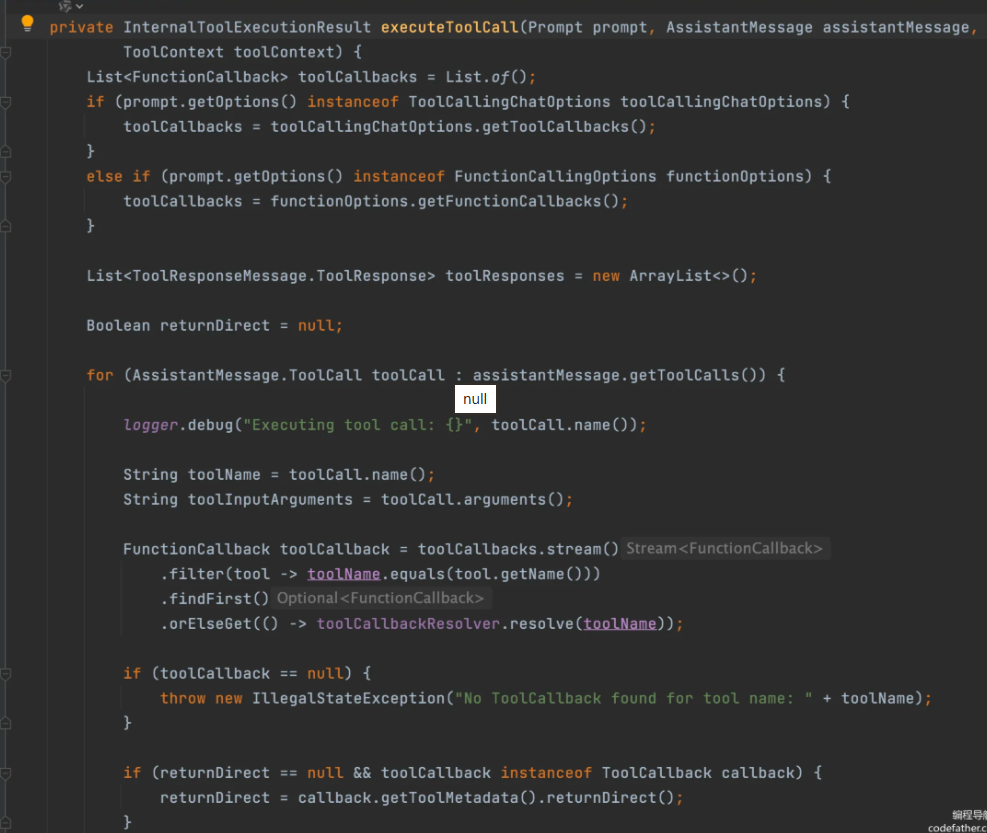
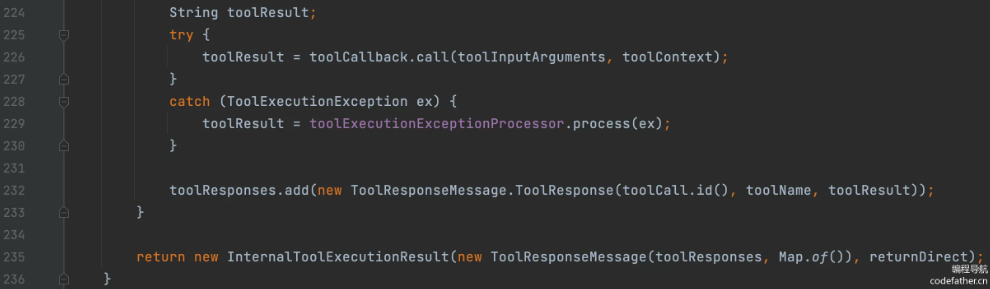
对于这段源码的解析:
请求初始化
用户发起对话请求,框架构建 Prompt 对象,从 Prompt 配置中获取可用的 ToolCallback/FunctionCallback 列表(已注册的工具集合)。
AI 模型决策
将 Prompt 发送给 AI 大模型,模型判断是否需要调用工具:
- 无需调用:直接返回自然语言回答,流程结束
- 需要调用:返回包含 toolCalls 字段的 AssistantMessage,其中包含要调用的工具名、参数等信息
工具调用触发
ToolCallingManager(默认实现为 DefaultToolCallingManager)接管执行,遍历 AssistantMessage 中的每一个 ToolCall:
- 从 ToolCall 中提取工具名和参数字符串
- 在 ToolCallback 列表中按工具名匹配对应的工具实现
- 若未找到,通过工具回调解析器全局解析;仍未找到则抛出异常
工具执行
解析参数字符串为 Java 方法可接受的参数类型,调用对应 ToolCallback 的 call 方法执行业务逻辑(如查询数据库、调用第三方接口),并收集工具执行结果。
结果交付控制
从 ToolCallback 的 ToolMetadata 中读取 returnDirect 标识:
-
returnDirect 为 true:工具执行结果直接返回给用户,不经过 AI 模型二次处理
-
returnDirect 为 false(默认):将工具结果封装为 ToolResponseMessage,塞回对话上下文,再次发送给 AI 模型
默认模式下,AI 模型基于工具结果生成自然语言回答,最终返回给用户。
上下文清理
请求结束后,自动清理 ToolContext(ThreadLocal 存储)避免内存泄漏,释放相关资源,完成一次完整的工具调用流程。
框架控制的工具执行
这是默认且最简单的模式,由 Spring AI 框架自动管理整个工具调用流程。所以我们刚刚开发时,基本没写几行非业务逻辑的代码,大多数活儿都交给框架负重前行了。
在这种模式下:
- 框架自动检测模型是否请求调用工具
- 自动执行工具调用并获取结果
- 自动将结果发送回模型
- 管理整个对话流程直到得到最终答案
用户控制的工具执行
对于需要更精细控制的复杂场景,Spring AI 提供了用户控制模式,可以通过设置 ToolCallingChatOptions 的 internalToolExecutionEnabled 属性为 false 来禁用内部工具执行。
1
2
3
4
5
|
// 配置不自动执行工具
ChatOptions chatOptions = ToolCallingChatOptions.builder()
.toolCallbacks(ToolCallbacks.from(new WeatherTools()))
.internalToolExecutionEnabled(false) // 禁用内部工具执行
.build();
|
然后我们就可以自己从 AI 的响应结果中提取工具调用列表,再依次执行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
// 创建工具调用管理器
ToolCallingManager toolCallingManager = DefaultToolCallingManager.builder().build();
// 创建初始提示
Prompt prompt = new Prompt("获取编程导航的热门项目教程", chatOptions);
// 发送请求给模型
ChatResponse chatResponse = chatModel.call(prompt);
// 手动处理工具调用循环
while (chatResponse.hasToolCalls()) {
// 执行工具调用
ToolExecutionResult toolExecutionResult = toolCallingManager.executeToolCalls(prompt, chatResponse);
// 创建包含工具结果的新提示
prompt = new Prompt(toolExecutionResult.conversationHistory(), chatOptions);
// 再次发送请求给模型
chatResponse = chatModel.call(prompt);
}
// 获取最终回答
System.out.println(chatResponse.getResult().getOutput().getText());
|
这样一来,我们就可以:
- 在工具执行前后插入自定义逻辑
- 实现更复杂的工具调用链和条件逻辑
- 和其他系统集成,比如追踪 AI 调用进度、记录日志等
- 实现更精细的错误处理和重试机制
异常处理
springai通过ToolExecutionProcessor接口实现来灵活的异常处理机制
1
2
3
4
5
6
7
|
@FunctionalInterface
public interface ToolExecutionExceptionProcessor {
/**
* 将工具抛出的异常转换为发送给 AI 模型的字符串,或者抛出一个新异常由调用者处理
*/
String process(ToolExecutionException exception);
}
|
默认实现类 DefaultToolExecutionExceptionProcessor 提供了两种处理策略:
alwaysThrow 参数为 false:将异常信息作为错误消息返回给 AI 模型,允许模型根据错误信息调整策略alwaysThrow 参数为 true:直接抛出异常,中断当前对话流程,由应用程序处理
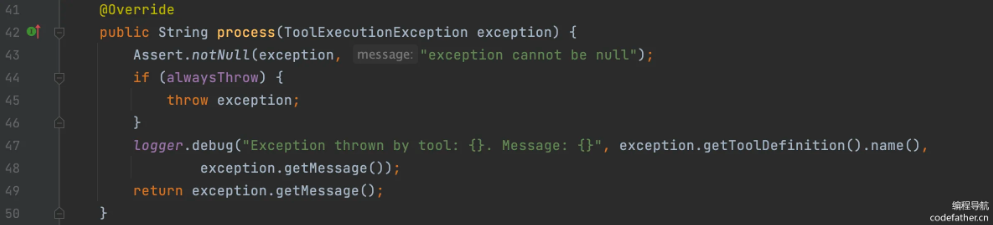
看源码发现,Spring Boot Starter 自动注入的 DefaultToolExecutionExceptionProcessor,默认即该策略。
可以根据需要定制处理策略,声明一个 ToolExecutionExceptionProcessor。
1
2
3
4
5
|
@Bean
ToolExecutionExceptionProcessor toolExecutionExceptionProcessor() {
// true 表示总是抛出异常,false 表示返回错误消息给模型
return new DefaultToolExecutionExceptionProcessor(true);
}
|
我们还可以自定义异常处理器来实现更复杂的策略,比如根据异常类型决定是返回错误消息还是抛出异常,或逐步实现重试逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
@Bean
ToolExecutionExceptionProcessor customExceptionProcessor() {
return exception -> {
if (exception.getCause() instanceof IOException) {
// 网络错误返回友好消息给模型
return "Unable to access external resource. Please try a different approach.";
} else if (exception.getCause() instanceof SecurityException) {
// 安全异常直接抛出
throw exception;
}
// 其他异常返回详细信息
return "Error executing tool: " + exception.getMessage();
};
}
|
总而言之,在我看来,就是对于一个异常的灵活处理机制,可以通过直接声明bean的方式,自定义去选择实现框架实现好的两个策略之一,要不就是自定义一个异常的处理机制
